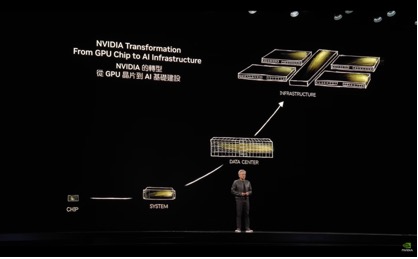
In a very short time, the phrase “AI factory” has become a staple of mainstream infrastructure conversations. It was used for the first time by NVIDIA CEO Jensen Huang in mid-2024 during his Computex keynote to describe a new type of data centre built specifically to power AI models. But these days the phrase has become shorthand for AI-optimised infrastructure.
While NVIDIA popularised the phrase in the context of modern GPU platforms, the broader idea isn’t entirely new. It’s often used to describe large GPU deployments or hyperscale data halls, but that can be misleading, as size alone does not define an AI factory.
At Computex Taipei 2025, Jensen Huang described AI factories in the following terms: “They’re not data centers of the past. These AI data centers, if you will, are improperly described. They are, in fact, AI factories. You apply energy to it, and it produces something incredibly valuable, and these things are called tokens.”
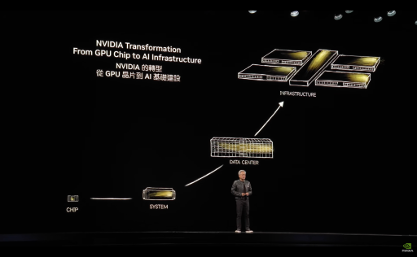
That definition encourages us to focus on what this specific type of data centre produces; rather than what it looks like on the outside. Put simply, an AI factory is infrastructure built intentionally to generate intelligence.
At its core, an AI factory is a production environment for AI workloads. It takes in data, and it generates tokens.
It is designed to:
An AI factory can begin with a small number of racks — or even a single, well-designed rack. What matters is whether the infrastructure has been designed to scale without re-architecture.
Much of the public discussion around AI factories focuses on scale. Take Tesla for example, the company is increasingly described not just as a car manufacturer but as an AI and robotics business. Its physical factories assemble vehicles and its AI infrastructure trains autonomous driving systems and robotics models.
The visible product (the vehicle) is only the surface. Beneath it sits a robotics ecosystem, automation systems, AI training infrastructure, and software pipelines that continuously improve performance.
In other words, the factory produces intelligence as much as it produces cars. And that is exactly what Jensen Huang means when he talks about AI factories. But not every organisation needs a gigafactory-scale deployment to qualify as running an AI factory.
A well-designed four-rack AI deployment built for model iteration and inference can be every bit as much an AI factory as a hyperscale environment.
High-performance AI infrastructure relies on multiple layers working together.
NVIDIA often visualises the AI factory as a full stack, beginning with electricity and data at the base, moving through certified systems and networking, and culminating in software, tokens, and business outcomes at the top. It’s a reminder to us all that GPUs alone are not the factory, they are one layer in a broader system.
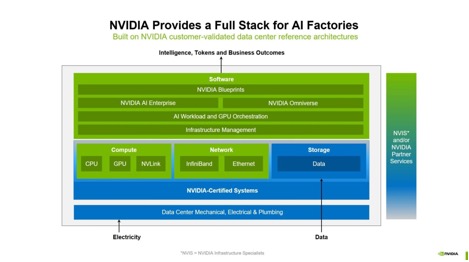
At a practical level, those layers break down into five domains:
Compute
GPU architecture, memory bandwidth, and interconnect design must match the workload.
Networking
AI workloads generate significant east-west traffic. Latency and bandwidth directly affect utilisation.
Storage
Training performance is often gated by data throughput rather than GPU capability. Storage design determines how efficiently models can be fed.
Cooling and power
Density planning and thermal consistency influence both performance stability and future expansion.
Software
Container orchestration, scheduling, MLOps tooling, and reproducibility determine whether experimentation can transition into production.
A strong compute layer cannot compensate for under-designed networking or storage. And a well-designed hardware stack will still struggle if the software layer is fragmented. The stack only works when the layers are designed together.
We structure our NVIDIA practice around Compute, Networking, Storage, and Software because those areas shape how a platform performs, scales, and operates over time. That structure mirrors how we design systems in practice and how we guide customers through trade offs early on.
Before designing any AI infrastructure, the first question should always be about workload.
Training a large foundation model behaves very differently from running low-latency inference across thousands of users. HPC workloads stress storage differently to generative AI. Drug discovery pipelines behave differently again.
There is no universal blueprint. In practice, AI deployments tend to fail at the integration points:
The difference between a GPU cluster and an AI factory is foresight. An AI factory is designed with scaling in mind from day one, and with a clear understanding of cost-per-token or cost-per-training-run economics.
Very few AI factories begin at full scale. Most start with a defined workload and a contained deployment. The risk lies not in starting small, but in starting without architectural discipline.
For some teams (particularly within research and education), that first step may be a tightly defined deployment such as a DGX Spark[1] -based environment. When treated properly, it becomes a practical test bed. A place to understand how workloads behave before ‘thinking bigger’.

Designing the first rack properly means understanding workload behaviour early and selecting compute, networking, storage, cooling, and software as a balanced system rather than as separate components.
Inference (running trained models in production) is often where architecture is tested hardest. Unlike training, it typically runs continuously as a distributed service, with many concurrent workloads sharing infrastructure. Once models are deployed, the platform must support predictable latency, sustained throughput, and operational stability. Designing with inference in mind from the first rack ensures that scaling is extending a system that is already built for production. And then you have yourself an AI factory.
As AI workloads mature, the question is no longer whether GPUs are powerful enough. It is whether the surrounding infrastructure is designed to support continuous model development and inference. An AI factory is simply a disciplined approach to answering that question.
If you are planning your first AI deployment, begin with workload mapping rather than GPU count.
If you are already running AI infrastructure, examine how the layers interact under real load.
And, if you are at either stage, reach out to our team for a conversation on how your current design behaves under load and define a path forward that supports growth.
And if you want to go deeper into the architectural decisions behind AI factories, explore our Compute, Networking, Storage, and Software deep dives across our NVIDIA Hub.