Rail-Optimised Networking: How NVIDIA is Rethinking AI Network Design in the Data Centre
Release date: 23 April 2025
A blog by Allan Kaye, CEO and co-founder at Vespertec
Everywhere you look, AI applications, and the NVIDIA GPUs used to run them, are delivering stellar results. The latest MLPerf benchmarks show HGX B200s performing at 12x that of the A100 range in LLM training, marking enormous progress in just 2 years. However, operating the hardware at scale isn’t without its challenges – or costs. To ensure maximum ROI, users need to take care to optimise connectivity.
The first step is recognising that it isn’t just about having the best chips. A car can have the most powerful engine in the world, but if it’s got the wrong tyres, a bulky chassis, or slow gearbox, it won’t perform as well as it could. In the same way, an organisation might be using NVIDIA’s most advanced hardware – but if it’s not optimised with the latest design principles, it won’t be getting the most out of that technology.
In our experience, one of the most overlooked areas of large-scale AI architecture is network topology. It can be a blind spot for even highly knowledgeable enterprise infrastructure teams. To help you understand how rail-optimised topology can supercharge GPU servers, let’s break down a more familiar configuration – and why it may not be suitable for AI clusters.
Why Move Away from Leaf and Spine Architecture?
As you may know, the default and familiar configuration is leaf and spine, which has dominated data centre architecture for years. For the uninitiated, leaf and spine topology connects leaf switches (which aggregate traffic from the server) to spine switches, which connect the network.
This configuration has been ubiquitous for years – and with good reason. It’s a massive improvement upon older three-tier architecture, typically consisting of a core, a layer for aggregation and distribution, and an access layer. With these, only one path between switches can be activated at any one time, meaning high latency and an increased likelihood of bottlenecks.
Leaf and spine’s innovation was to create a two-layer topology. The spine layer fields all connections and allow a single hop between leaf switches, massively reducing latency.
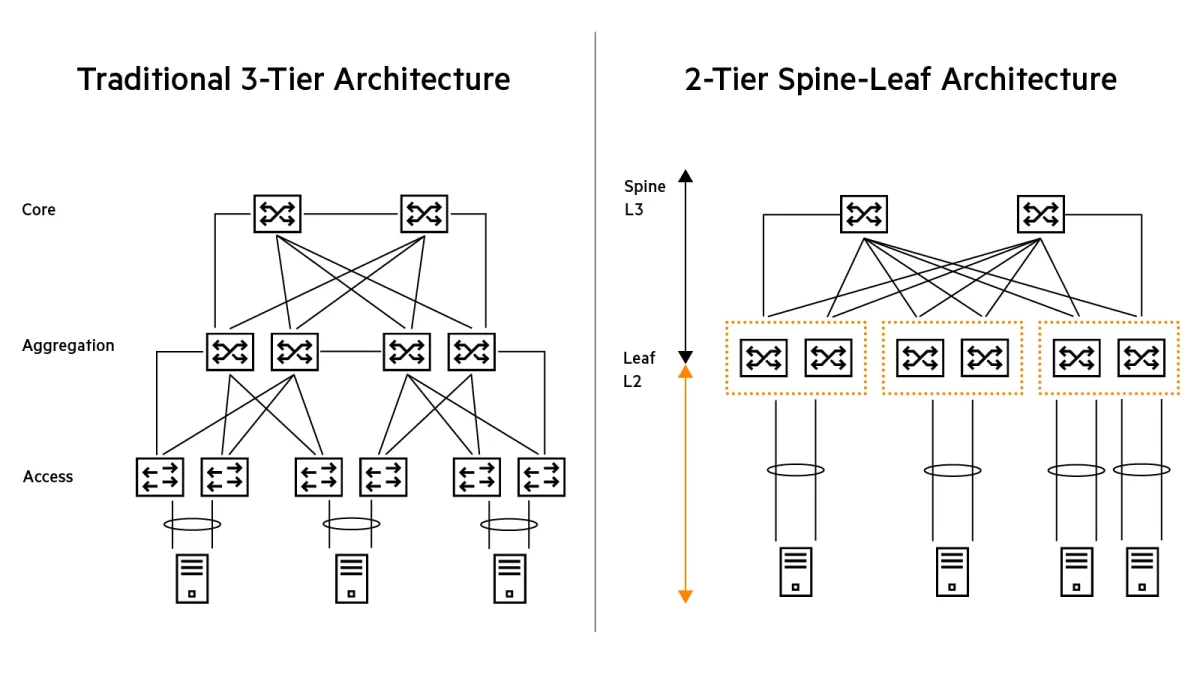
(1)
The issue now, of course, is that AI clusters are thirsty for compute. These workloads are more bandwidth-intense than anything we’ve seen before, and leaf and spine configurations can sometimes struggle to make the grade where large volumes of GPUs are involved. Meanwhile, all-to-all communication patterns confuse spine-layer links and create uneven load distributions between switches.
As a result—just as leaf and spine usurped three-tier systems for general data centre networking purposes—rail-optimised topologies are overtaking leaf and spine for large-scale AI clusters.
How Does Rail Differ?
Rail-optimised topologies began with engineers looking squarely at the problem: AI operations required more bandwidth than existing configurations could handle. For example, the “Allreduce operation”, which is among the most common for AI fabrics, requires nearly all communication between nodes to occur across the same NIC ports of each host.
Knowing this, the topology can be designed so that no GPU is more than one hop away from any other in the network, improving inter-GPU communication. Rail-optimised topology builds upon the principles that made leaf and spine revolutionary and improves upon them for this specific type of deployment. It restructures the network into parallel, high-bandwidth data paths. These ‘rails’ act as direct communication channels between the leaf switch and a subset of GPUs, meaning data no longer needs to traverse multiple leaf switches. This significantly lowers congestion and latency.
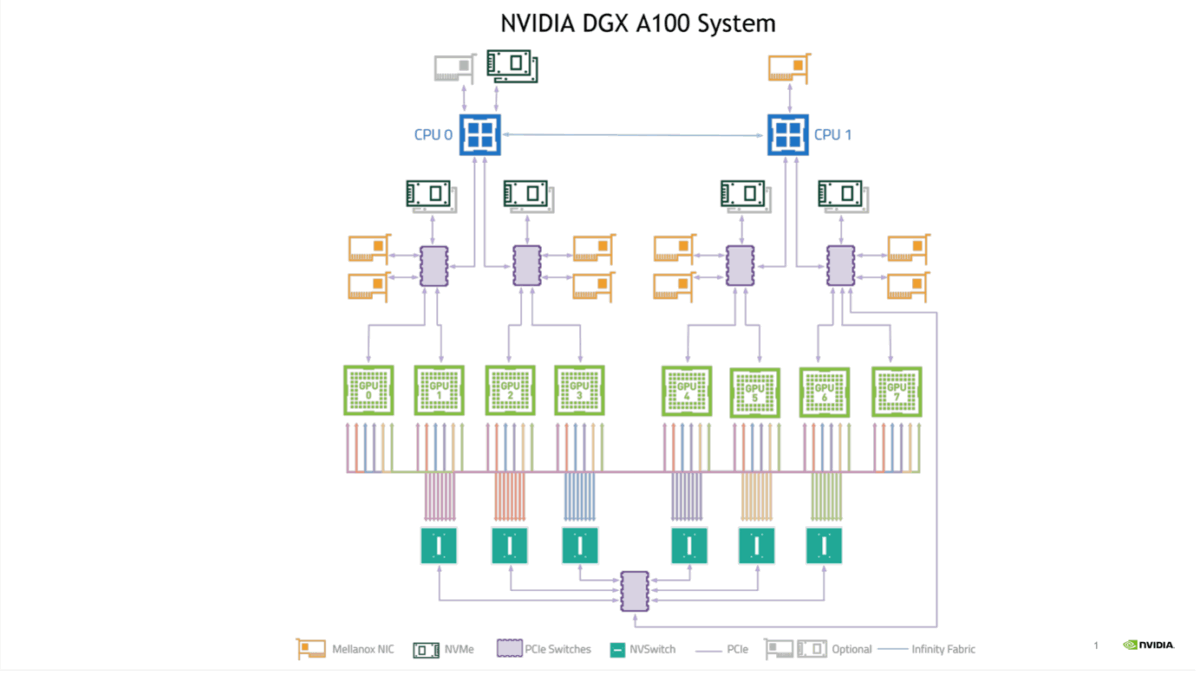
In large clusters, GPU connectivity is required across the network (in addition to NVLink switching within the individual servers). For example, take NVIDIA’s HGX and DGX servers, which are 8-way GPU systems. Each system features 8 network cards (1 per GPU) to handle “east-west” traffic (i.e. comms within the cluster between GPUs). In current topologies, NVIDIA’s ConnectX-7 cards run up to 400Gb/s total bandwidth. Next-gen ConnectX-8 cards are expected to double this, supporting 800Gb/s total bandwidth, which will make the need for optimised architectures even more acute.
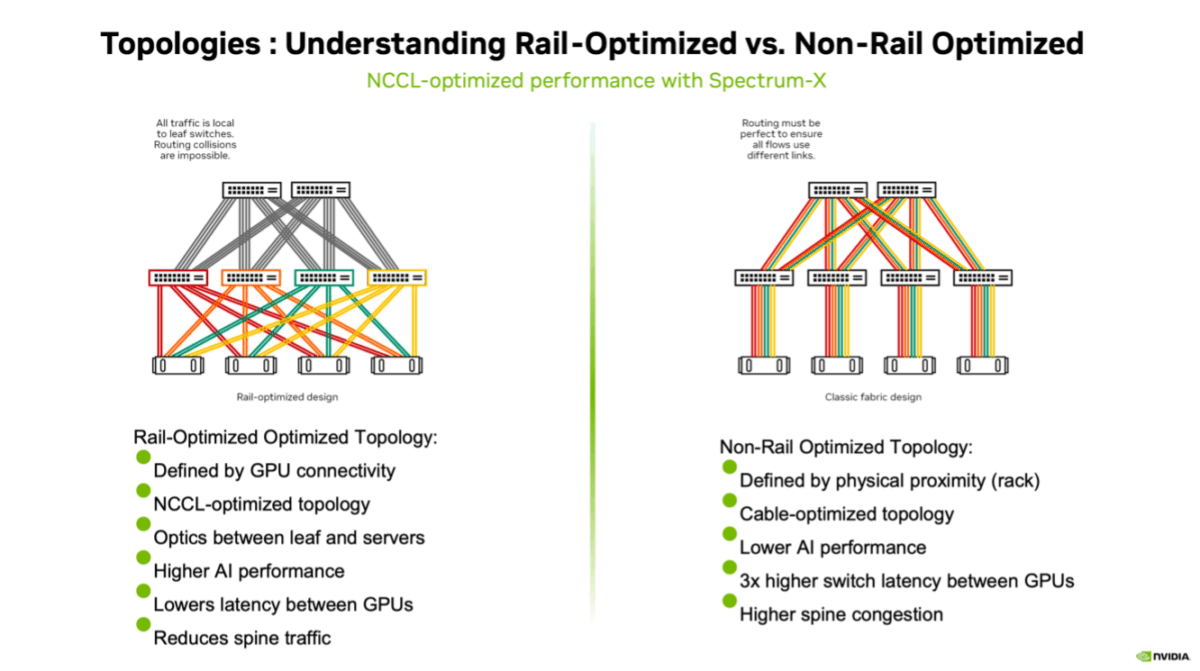
See here some excellent diagrams provided by our friends at NVIDIA.
This means, in a given system, GPU 1 will be paired with network card 1 and connected to switch 1; GPU 2 pairs with network card 2 and connects to switch 2, and so on throughout. As a result, GPU 1 in each system is only ever one hop away from GPU 1 in another system in the cluster, and the same goes for each other GPU. This creates a non-blocking “all-to-all” fabric for all servers in a large-scale AI network.
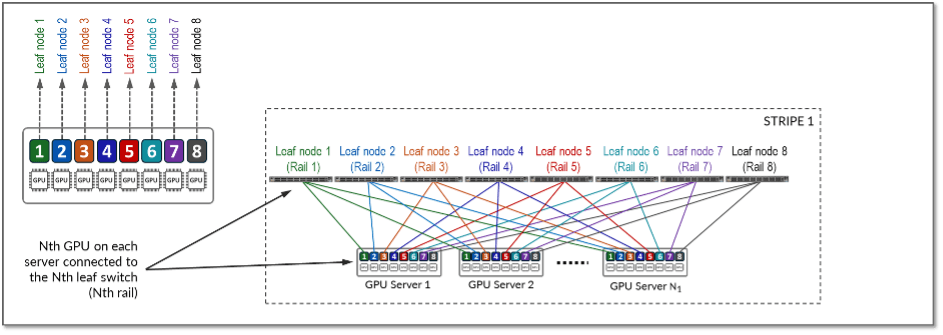
(2) Illustration of east-west connections
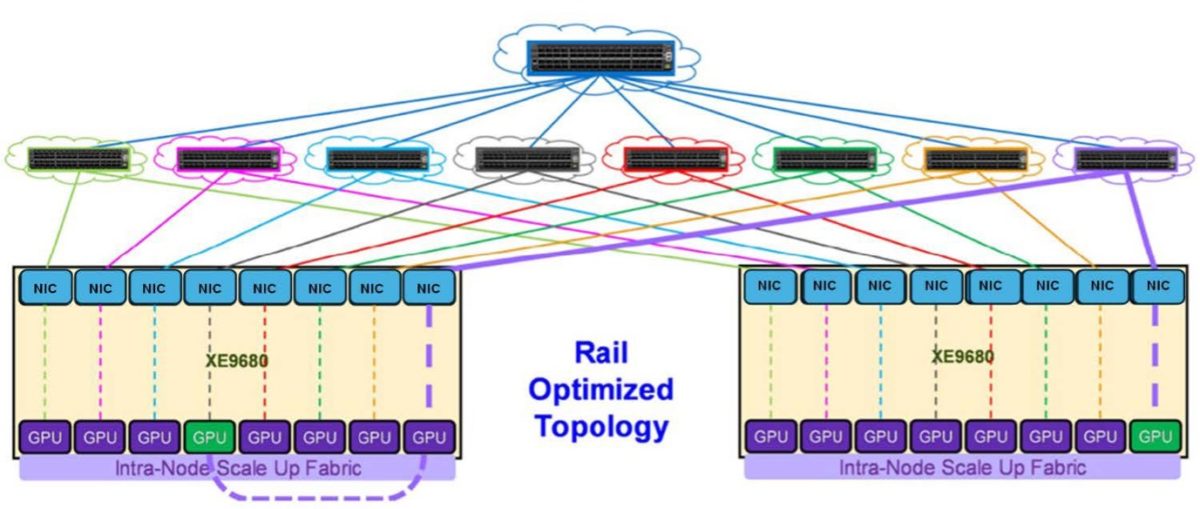
(3) A ‘zoomed-in’ visualisation of GPU 8 communicating with GPU 8 in another system.
Why Does Rail-Optimised Networking Matter?
It’s hard to overstate how important rail-optimised topology is for AI clusters. All of NVIDIA’s reference architecture features rail-optimised topology as best-practice, and all its benchmarks are set on rail-optimised architecture. If you need any more evidence, NVIDIA’s Israel-1 supercomputer – among the most powerful in the world – also utilises Rail-optimised networking.
The key takeaway here, then, is simple: if you haven’t already switched to rail-optimised topology to link together a bunch of your H100s, GH200s, (or even B200s), there’s no better time to look into it.
If you’re using NVIDIA’s latest GPUs, but not following the latest design principles, then there’s a fair chance you’re not getting the most out of your architecture. You might save on cabling costs in the short term, but your hardware will be unable to deliver anywhere near the same performance (and ultimately ROI) that it otherwise could.
There are dozens of ways to optimise your architecture. Whether it’s the latest topography, or advanced networking platforms like Spectrum X and InfiniBand, we fine-tune AI architecture and ensure that every single element is working to provide the maximum value for our clients. We do this by testing, re-testing, and thoroughly researching customers’ business needs, and using our decades of experience to tailor solutions that suit them.
If you’d like to know more, take a moment to get in touch.
Sources
